题目设计
本题给出了数千张小猫的图片,数据分为两类:AI生成和人工拍摄,期望选手对数据完成区分,即完成 人工智能生成图片伪造检测技术。
WriteUp
关于深度伪造图片检测的其中一种方向是:把 GAN 生成 “频域不一致” 量化为检测特征。
Zhang. 等人发现 GAN 图像在 DCT/FFT 域的高频能量显著低于真实图像 IEEE T-IFS 2020 :Leveraging High-Frequency Components to Expose GAN-Forged Faces
之后人们就走上了,通过频域分析模型生成模式方案中。
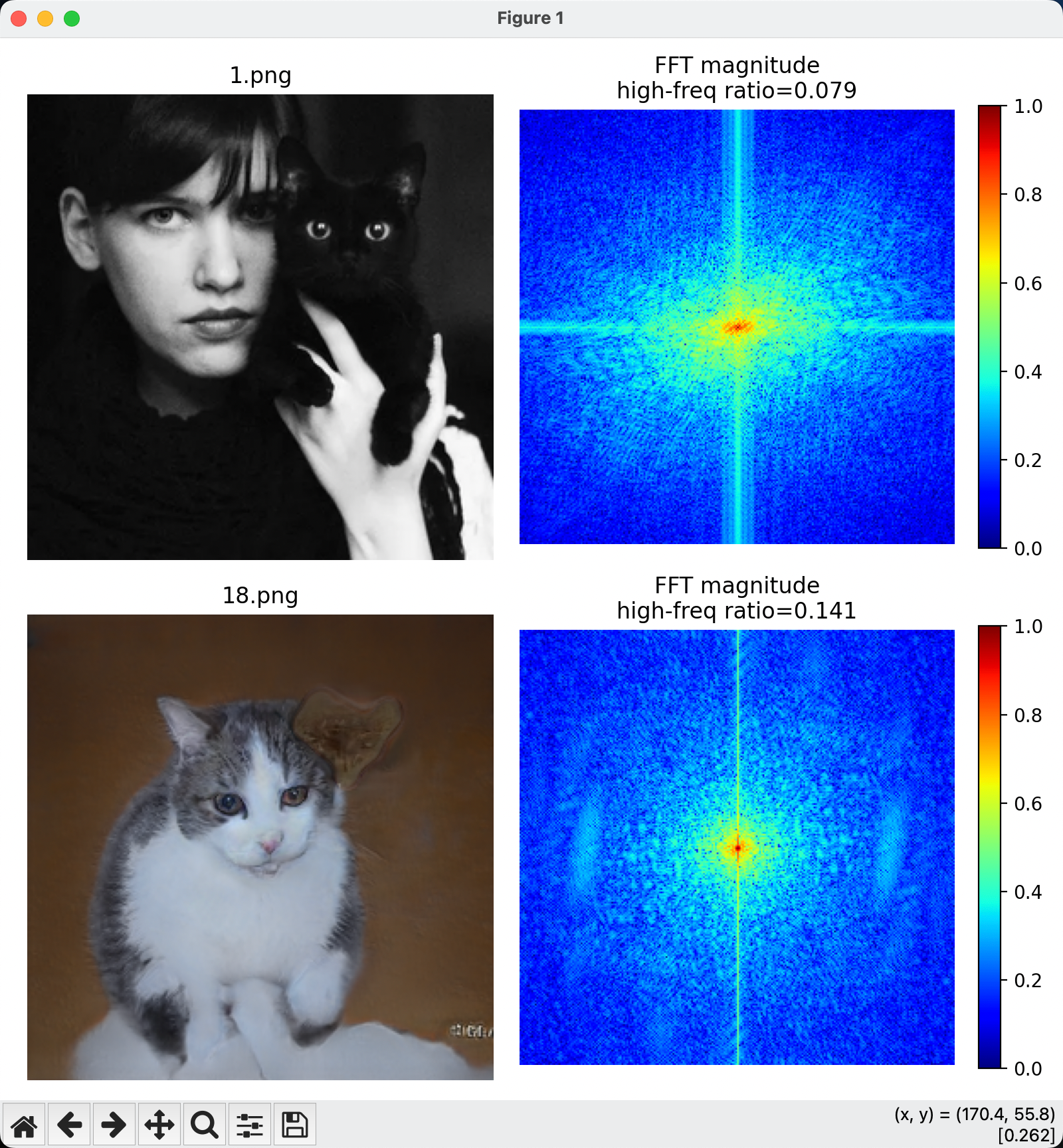
上图展示了不同的两幅图片,在截取高频后统计量之间的区别。
更通常的,对于 GAN/Deepfake 图像,通常 high-freq ratio 在 0.15 以上,而真实照片的high-freq ratio低于 0.10。
涉及的两个重要超参数分别是:
- THRESHOLD_RADIUS_RATIO :多少百分比算“高频”
- Delta :大于(小于)多少算伪造(真实)图片
最终exp
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
| import os
import numpy as np
from PIL import Image
import torch
import torch.fft
THRESHOLD_RADIUS_RATIO = 0.85
delta = 0.125
def load_gray_tensor(path: str) -> torch.Tensor:
img = Image.open(path).convert("L")
arr = np.asarray(img, dtype=np.float32) / 255.0
arr = (arr - 0.5) * 2
return torch.from_numpy(arr)[None, None, :, :]
def fft_magnitude(tensor: torch.Tensor):
fft = torch.fft.fft2(tensor)
fft_shift = torch.fft.fftshift(fft, dim=(-2, -1))
mag = torch.abs(fft_shift)
mag_log = torch.log1p(mag)
mag_log -= mag_log.min()
mag_log /= mag_log.max() + 1e-8
return mag_log[0, 0].numpy()
def high_freq_ratio(mag: torch.Tensor, ratio: float = THRESHOLD_RADIUS_RATIO):
h, w = mag.shape[-2:]
cy, cx = h // 2, w // 2
Y, X = torch.meshgrid(
torch.arange(h, dtype=torch.float32) - cy,
torch.arange(w, dtype=torch.float32) - cx,
indexing="ij"
)
dist = torch.sqrt(X ** 2 + Y ** 2)
radius = min(cy, cx) * ratio
mask_high = dist >= radius
total_energy = mag.sum()
high_energy = mag[..., mask_high].sum()
return (high_energy / total_energy).item()
f = open('耄耋/exp/res.csv', 'w')
f.write(f'idx,detection\n')
real_dir = '耄耋/exp/dataset'
for fname in os.listdir(real_dir):
if fname.lower().endswith(('.png')):
file = os.path.join(real_dir, fname)
tensor = load_gray_tensor(file)
mag_np = fft_magnitude(tensor)
ratio = high_freq_ratio(torch.abs(torch.fft.fftshift(torch.fft.fft2(tensor))))
res = 'fake' if ratio > delta else 'real'
f.write(f'{fname[:-4]},{res}\n')
f.close()
|
吐槽
由于我的(也许是Koali的)蠢蛋问题,每次这样的校验题目,总是会留下非预期 orz
下面是一份赛场选手的非预期WrtieUp(By晨曦)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| import requests
import copy
url = 'http://172.36.111.73:5000/upload'
headers = {"Content-Type":"multipart/form-data; boundary=----WebKitFormBoundaryFgG5yR6Y9veJTmnI"}
file_data = open('res.csv','r').read().split('\n')
cat_data = {i:"fake" for i in range(2293)}
data = """
------WebKitFormBoundaryFgG5yR6Y9veJTmnI
Content-Disposition: form-data; name="file"; filename="result.csv"
Content-Type: text/csv
[file_data]
------WebKitFormBoundaryFgG5yR6Y9veJTmnI--
""".strip()
new_data = "idx,detection\n"
for i in range(1,2293):
fake_tmp = copy.copy(file_data)
real_tmp = copy.copy(file_data)
real_tmp[i] = real_tmp[i].replace('fake','real')
fake_data = '\n'.join(fake_tmp)
real_data = '\n'.join(real_tmp)
fake_data = data.replace('[file_data]',fake_data)
real_data = data.replace('[file_data]',real_data)
fake_res = requests.post(url,data=fake_data,headers=headers).text
real_res = requests.post(url,data=real_data,headers=headers).text
fake_num = float(fake_res.split('%')[0].split(' ')[1])
real_num = float(real_res.split('%')[0].split(' ')[1])
if fake_num >= real_num:
tmp = str(i-1) + ',fake\n'
else:
tmp = str(i-1) + ',real\n'
new_data += tmp
open('res1.csv','w').write(str(new_data))
|